AIの2026年問題とは? データの枯渇で何が起きるかを解説
AI(人工知能)は、インターネットなどから大量のデータを読みとって学習しています。しかし、2026年にはインターネット上から良質なデータが枯渇するという「2026年問題」が、専門家から指摘されました。本記事では、AI発展の歴史に触れながら、2026年問題の概要と対応策、そしてこれからのAIについて解説します。
AIの2026年問題とは?
AIの2026年問題とは、LLM(LargeLanguageModels:大規模言語モデル)のトレーニングに必要な高品質なデータが、2026年には不足すると懸念されていることです。LLMとは言語を生成するAIのコア技術で、ChatGPTなどに用いられています。
スチュアート・ラッセル教授による警鐘
2026年問題を指摘したのは、AI研究の権威であるアメリカ・カリフォルニア大学バークレー校のスチュアート・ラッセル教授です。2023年7月、国際電気通信連合(ITU)が開催した「AIforGood(AIに関する国際サミット)」において、今後7年間の展望を聞かれた際、「LLMをより大きくして、より多くのデータを使って学習させる方法は終わりつつあり、データは底をつき始めている」という旨のコメントを残しています。
LLMの開発には、膨大な量の質のよいデータが必要です。データは主にインターネットから収集されますが、それが近い将来枯渇すると、ラッセル教授は警告しています。
参照元:ITUINTERVIEWS@ITUAIforGoodGlobalSummit:StuartRussell
データの枯渇で生じる機械学習の減速
2026年問題については、アメリカの研究グループ「Epoch」が2022年11月に論文を発表しました。これによると、AIの学習に必要な高品質のデータは2026年まで、低品質のデータは2030年から2050年までの間に、ビジュアルデータは2030年から2060年までの間に枯渇します。そして、これが原因となり機械学習の進歩が止まるとしています。ただ、データ学習がより効率化することも考えると、2040年までにAIの進歩が大幅に減速する確率は、約20%とのことです。
参照元:「AIの学習データが底をつく」'2026年問題'の衝撃度とその対策とは?|Yahoo!ニュース
ここでいう高品質なデータとは、書籍やニュース記事、科学論文のほか、ウィキペディアなどの編集されたコンテンツです。一方、X(旧Twitter)などの編集が行われていないテキストは、低品質のデータと分類されています。
新しい学習データをいかにして確保するかは、AI開発企業が抱える課題です。というのも、データを供給する側も厳しい姿勢を取り始めているからです。たとえばXは2023年7月、一時的に閲覧制限を導入し、多くのユーザーを混乱させました。この制限をかけた理由のひとつは、AI開発企業による膨大なデータスクレイピング(データの抽出)が、Xのシステムに負荷をかけたからと考えられています。
AIはどのように発展してきた?今までとこれから
AIの2026問題にどう対応すべきかを考える前に、AI発展のプロセスを整理しましょう。AIは、常に脚光と称賛を浴びてきたのではなく、ブームと低調な時期を繰り返しながら進化してきたことがわかります。
第一次人工知能ブーム
最初の人工知能のブームは1950年代後半から1960年代とされています。
1956年、アメリカで開かれたダートマス会議で、人工知能(AI:ArtificialIntelligence)という言葉が初めて使われました。実はAIについての明確な定義はありませんが、一般社団法人人工知能学会によると、「大量の知識データに対して、高度な推論を的確に行うことを目指したもの」とされています。
第一次人工知能ブーム期に、人間の思考のプロセスを記号で表現・実行する「推論」と、場合分けをしながら解き方のパターンを探し出す「探究」が、コンピュータによって可能になりました。この技術により、コンピュータがパズルや迷路など、明確なルールがある問題を解くことは実現しました。しかし、現実社会の複雑な問題は解けないことが明らかになると、ブームは下火となり、AI研究は失速して冬の時代を迎えます。
第二次人工知能ブーム
第二次人工知能ブームが起こったのは1980年代です。きっかけとなったのが、AI研究から生まれたエキスパートシステムです。このシステムはexpert(専門家)の名が示す通り、知識をルールとして教えこめば、特定の問題に対して専門家のように問題解決へと導けます。
エキスパートシステムは多くの企業で導入され、現在に至っています。たとえば、ECサイトにアクセスした際、閲覧履歴から類似商品をユーザーに勧める機能や、ニュースサイトを閲覧したとき、興味がありそうな記事を表示する機能は、エキスパートシステムの代表例です。
商用化されたエキスパートシステムですが、当時のコンピュータには自動で情報を収集する能力がなかったため、人が手動で膨大な量の情報をインプットしなければなりませんでした。また、例外や矛盾したケースへの対応も技術的に困難でした。そのため、エキスパートシステムは特定の分野に限定せざるをえず、AIブームは再び冬の時代に向かいます。
第三次人工知能ブーム
2000年代から現在まで続いているのが、第三次人工知能ブームです。第三次ブーム到来の予兆は、1990年代から見受けられました。たとえば、1997年にチェス専用スーパーコンピューター「ディープブルー」が、チェスの世界王者ゲイリー・カスパロフ氏に勝利したことは、「AIが初めて人類に勝った」として世界的に大きな注目を集めました。
第三次人工知能ブームの特徴は、機械学習の実用化とディープラーニングです。
機械学習とは、ビッグデータと呼ばれる大量のデータを読み込んだAIがルールやパターンを発見し、そのルールに沿った予測や判断をすることです。ビッグデータは、明確には定義されていませんが、テキスト・画像・動画・音声など、さまざまな種類・形式からなる巨大なデータを指します。「Volume(量)」「Variety(多様性)」「Velocity(速さ)」を示す3つの「Ⅴ」のレベルが高いことが条件とされています。
参照元:3.公的統計におけるビッグデータの活用の動向|総務省
ディープラーニングは、機械学習の手法のひとつです。多数の層からなるニューラルネットワークを使って行うことから、深層学習とも呼ばれます。ディープラーニングの特筆すべき点は、特微量(feature)をAI自らが発見できることです。featureとは「特徴」を意味する英語で、特微量は予測を立てるための変数を指します。たとえば、あるソフトドリンクの売上予測をする際は、価格・天候・陳列する場所といった要素が特微量に挙げられます。特微量の選定が予測の精度に大きな影響を及ぼすことは、いうまでもありません。
機械学習においては特微量を人が設定していましたが、ディープラーニングでは人の手を借りずにAI自らが特微量を見つけだせるので、より精度の高い予測が可能になります。AI自らデータから学習し、特微量を発見することは、AI研究において非常に画期的なことです。
これらの新しい技術により、2012年には将棋ソフト「ボンクラーズ」がプロ将棋士に、2016年には囲碁ソフト「アルファ碁」がプロ囲碁棋士に勝利しました。チェスや将棋より盤面が広く、対局のパターン数が非常に多い囲碁では、AIが人に勝つまでに時間がかかるとされていたため、アルファ碁の勝利は非常に衝撃的でした。
現在、AIは医療や交通、物流から災害対策に至るまで、さまざまな分野で生活を支えています。たとえば医療画像診断では、ディープラーニングが膨大な量の画像データから病気の特徴を学び、高い精度で病変を検出することが可能です。また、安全性が求められる自動運転技術においても、ディープラーニングは車の周囲の状況を認識し、運転動作を決定することに用いられています。
生成AIブームによる大規模化と「2026年問題」
2022年3月、アメリカのOpenAIが対話型AIであるChatGPTをリリースしました。これを機に、生成AIブームが起こります。
ジェネレーティブAI(GenerativeAI)とも言われる生成AIは、さまざまなコンテンツを作る能力を持ちます。従来のAIのように、自動で学習したデータをもとにして予測・特定するのではなく、オリジナルのコンテンツを生成することを目的にして学習する点が大きな違いです。それまで、0から1を創造することは人にしかできない領域とされていましたが、生成AIの誕生によって、よりクリエイティブな作業も自動化できるようになります。テキストだけでなく、画像、音声や音楽、動画なども生成可能です。
前述のように、LLMをコア技術とする生成AIの学習には、大量のテキストデータが必要です。大量のデータを使うことで、LLMはさらなる大規模化を果たしてきました。しかし、肝心のデータが2026年に枯渇すると警告され、大規模化は終わりを迎えると考えられています。
シンギュラリティに到達する「2045年問題」
今後のAIの進化を考える際、避けて通れないのがシンギュラリティ(Singularity:技術的特異点)です。シンギュラリティは、直訳すると「特異点」を意味します。AIが進化する過程で、「いずれは人間の知能を超えるときがくるのでは」と言われており、その転換点がシンギュラリティとされています。
アメリカのAI研究の権威であるレイ・カーツワイル博士は、2029年にAIが人間と同じレベルの知能を手に入れ、その後2045年にはシンギュラリティに達すると予想しました。これを「2045年問題」と呼んでいます。
2045年問題に関しては、さまざまな考えがあります。人間とAIが共存する、AIが人間の行動や思考をサポートするといった楽観的な意見や、AIが独走し、人間にとって有益な存在にならないという悲観的な意見のほか、「機械には目標がない」として、シンギュラリティ自体こないという考えもあります。
2026年問題は何が問題?
AIが学習するための高品質なデータが枯渇することで、具体的に起こる弊害として、主に以下のものが挙げられます。
生成データの質が低下する
AIの学習には高品質なデータが大量に必要です。たとえばChatGPTは、3,000億語のテキストデータで学習していると言われています。しかし、AIの学習データが質・量ともに不十分だと、アウトプットのクオリティは低くなると懸念されています。
実際、アメリカのスタンフォード大学は2023年7月、ChatGPTの知能が急に低下したという研究結果を公開しました。これによると、ChatGPTの計算能力が数カ月の間に、約98%から約2%にまで低下したとのことです。
参照元:ChatGPTの知能が急激に低下しているとの研究結果、単純な数学の問題の正答率が数カ月で98%から2%に悪化|GIGAZINE
また、2016年にMicrosoftがXのコンテンツを使ってAI「Tay(テイ)」をトレーニングしたところ、ほかのユーザーから大量の差別的発言を浴びる過程でその内容を学習し、差別的なツイートを生成したというケースもあります。
非公開データが活用される懸念がある
高品質なデータが使い果たされつつあるため、AI開発企業が非公開のデータや機密性の高いデータ、著作権のないデータを勝手に使うことも懸念されています。
これについては、海外で訴訟問題に発展しています。たとえばOpenAIは、複数の著者から著作権が侵害されたとして、訴訟を起こされています。
2026年問題に対応するには?
AIが学習するためのデータが枯渇するという、AI進化の根幹を揺るがす問題に対し、AI開発企業はどのような対策を立てているのでしょうか。
従来のメディアとの提携
インターネット以外から、AIが学習するためのデータを収集する動きが広がりつつあります。アメリカのいくつかのAI開発企業は、通信社や大手出版社などのメディアに対価を払って、過去のニュース記事などの良質なコンテンツを確保しようとしています。インターネットから大量のデータを収集するより、規模は小さくともクオリティの高いデータを利用するほうが、精度が高くなる可能性に期待が集まっています。
参照元:「AIの学習データが底をつく」'2026年問題'の衝撃度とその対策とは?|Yahoo!ニュース
合成データの利用
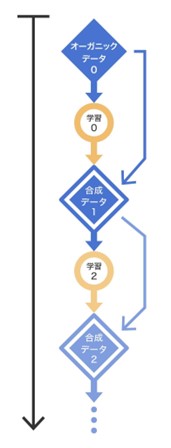
AI自身が生成したデータを、学習データとして利用するのもひとつの方法です。人が作ったデータをオーガニックデータとするのに対し、AIが作ったデータを合成データと位置づけます。AIが学習のために合成データを使うことが、近い将来一般的になると見られています。
データ汚染によるモデル崩壊
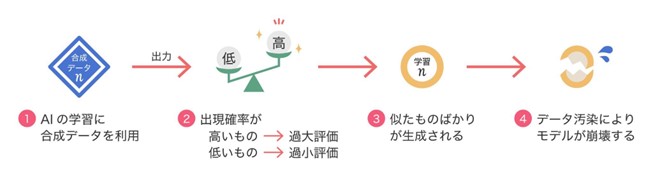
AIによる合成データの利用が増える一方で、問題点も指摘されています。
イギリスのオックスフォード大学およびケンブリッジ大学が2023年に発表した論文では、何世代にもわたって合成データでAIが学習を続けると、データ汚染によりモデルが崩壊するとしています。
論文によると、オーガニックコンテンツで学習したAIを第0世代、第0世代が出したコンテンツで学習したAIを第1世代として、何世代もAIが学習を繰り返した場合、第9世代になるとAIのアウトプットは無意味なものになるとのことです。つまり、AIによる合成データが次世代の学習セットを汚染するので、世代を経るごとにAIが退行し、結果的に崩壊します。
参照元:「AIの学習データが底をつく」'2026年問題'の衝撃度とその対策とは?|Yahoo!ニュース
2026年問題を超えて発展が期待されるAI
現時点では、2026年問題をクリアする明確な方法が見つかっていません。しかし、AI研究者によってさまざまな技術が開発されています。
SLM(小規模言語モデル)
AI開発企業が研究を進めているのが、SLM(SmallLanguageMode:小規模言語モデル)です。LLMが大量の学習データを必要とするのに対し、SLMは研究論文や教科書のような高品質かつ専門性の高いデータで学習し、専門性の高い課題の解決を担います。
Microsoftは、2023年12月に小規模言語モデル「Phi-2」をリリースしました。厳選されたデータを学習に用いたPhi-2は、パラメータ数(言語モデルの性能を表す指標のひとつ)で見ると27億と小規模です。しかし、推理能力と言語理解能力に秀でており、最大25倍の大規模言語モデル(LLM)に匹敵する性能を持つとされています。
SLMは、LLMと比べて学習に必要なデータが少ないため、2026年問題を乗り切ることが期待できます。コスト面で優れていることも特長のひとつです。
自律型AIエージェント
生成AIの応用型として期待されるのが、自律型AIエージェント(AutonomousAgents)です。自律型AIエージェントは、設定されたゴールに対し、自律的に働いて完了させる能力があります。人による細かい指示設定は不要です。
たとえば目的を設定すると、AIはそれを達成するために何が必要かを自律的に考え、いくつかの必要なタスクに分類し、さまざまツールを使いながら、目的を完了させるまで行動します。途中でミスがないか確認し、問題があれば修正を加える機能もあります。
今以上に業務を自動化できるものとして、営業、在庫管理、顧客管理から人事、経理、研究開発に至るさまざまな分野で、自律的AIエージェントの活用が期待されています。
ワークマネジメントツールAsanaの新機能「AI Intelligence」でもAIが活用されている
Asanaはひとつのプラットホームで日々のタスク管理やプロジェクトマネジメント、個人目標の管理などをおこなうワークマネジメントツールです。新機能である「AI Intelligence」では、AIの能力が業務管理に活かされています。
例えば「スマートステータス」機能では、リアルタイムに業務の進捗状況や未解決課題の把握が可能です。業務上直面する可能性がある課題点を洗い出し、効率的な作業をうながす役割を果たします。
また、AIに業務上の質問を投げかけることができる「スマートアンサー」機能を活用すれば、過去のデータから最適な答えを導き出し、問題解決に寄与します。
さらには、個人の業務実績と業務特性を分析し、効果的な個人目標を設定してサポートする「スマートゴール」機能も実装予定です。これにより従業員の責任意識を向上させ、モチベーションアップを図れます。
一元的なワークフロー管理とAI Intelligenceを備えたAsanaは、AI導入により業務効率化と生産性向上を目指す企業にとって最適なソリューションです。
ガートナーでもトップリーダーに位置づけられているAsana
ガートナー(Gartner)は世界最大級のIT市場調査会社で、同社による評価はITベンダーや企業にとっての重要な参考資料となっています。ガートナーが2023年に発表した「共同作業管理のマジック・クアドラント」報告書では、Asanaがビジョンの完全性および実行能力が高い企業としてトップリーダーに位置付けられました。
Asanaはアメリカを本拠地とし、世界各国に拠点を構えて事業を展開しています。コラボレーションワークマネジメント市場(CWM)市場に強く、世界トップレベルの企業を顧客に持ち、ブランド認知度も非常に高い企業です。製品開発に顧客フィードバックを反映しており、非常に高い顧客満足度を獲得しています。このような実績やガートナーの高い評価から、Asanaを採用すれば日本企業のAI導入においても高い効果が得られると予想できます。
まとめ
学習データが枯渇するというAIの2026年問題は、AIの発展にブレーキをかけ、企業行動にも影響を与えかねない由々しき問題です。しかし、日々AIは進化し、課題を克服する動きも生まれています。今やAI活用は企業の成長に欠かせないものであり、今後もAIの進化を注視する必要があります。


